
hyndb
[CS] 자바 메모리 & GC 본문
1. 자바 메모리
- 자바 프로그램의 실행을 위해 사용되는 메인 메모리는 프로그램과 static 데이터가 저장되는 영역, heap 영역, stack 영역으로 구분된다.
1) 프로그램과 static 데이터가 저장되는 영역
- 프로그램 코드와 프로그램에 선언된 상수들 저장
- static으로 선언된 멤버 변수들 저장(클래스 변수)
- 이 영역의 상수나 변수들은 프로그램이 실행되는 동안 삭제되지 않는다.
2) Heap 영역
- 프로그램의 실행이 시작된 후 new 연산자에 의해 생성된 객체를 저장하는 영역
- 객체들은 가비지 컬렉션(GC)에 의해 제거되지 않는 한 프로그램이 끝날 때까지 heap영역에 남아있다.
3) Stack 영역
- 호출된 메소드의 매개변수와 호출한 메소드 내에서 선언된 지역 변수 등이 저장된 스택 프레임이 저장되는 영역
- 메소드의 수행이 끝나면 해당 스택 프레임도 제거된다.
- 스택이므로 메인 메소드가 가장 밑에 저장되고 그 위로 호출된 메소드의 스택 프레임이 순차적으로 쌓이게 된다.
public class Item {
private String name;
private int price;
public Item(String n, int p) {
// 기본 생성자
}
public static void main(String[] args) {
int aprice = 50;
String aname = "apple";
Item fruit = new Item(aname, aprice);
}
}
- main 메소드의 스택 프레임이 stack 영역에 만들어지고, 그 프레임에는 원시 타입인 int 형의 지역 변수 aprice에 50이 저장된다.

// int aprice = 50; String aname = "apple";
- String 객체인 aname이 heap 영역에 생성되고, "apple"이 저장된다.
- 메인 메소드의 스택 프레임에는 String 객체가 가리키는 레퍼런스가 aname에 저장된다.

// Item fruit = new Item(aname, aprice);
- Item 객체 생성되어 heap 영역에 저장되고, 인자로 보내진 aname 레퍼런스와 50이 새 스택 프레임에 저장되어 메인 메소드의 스택 프레임 위에 쌓인다.
- 메인 메소드의 스택 프레임의 fruit 에는 새로 생성된 객체를 가리키는 레퍼런스를 새로 저장한다.

- 위 Item 객체 생성 코드가 수행된 직후 메인 메소드의 스택 프레임이 삭제된다.
2. GC(가비지 컬렉션)
- 프로그램이 실행되는 도중 사용되지 않는 heap 영역의 객체들을 제거하는 원리
- 각 루트로부터 깊이 우선 탐색으로 도달 가능한 객체들은 놓아두고, 도달 불가능한 객체들을 제거한다.
1) 마크 청소 GC
- 다음과 같이 3단계로 구성된다.
① 마크 단계: 각 루트로부터 DFS(깊이 우선 탐색)를 수행하며 방문한 객체들은 '살아있는 객체'라고 마크(표시)한다.
② 청소 단계: 마크 안 된 객체들을 청소
③ 통합 단계: 살아있는 객체를 한 곳으로 옮기어 객체 간의 공백을 줄인다.

- 위 자바 메모리에서 살펴본 메모리 구조
- 가비지 컬렉션 수행 전 메소드의 실행이 스택 영역에 쌓인 상태

① 마크 단계 수행한 후
- DFS로 방문한 객체들은 마크(도달 가능)
- 마크하지 않은 객체들은 GC 대상(도달 불가능)

② 청소 단계 수행한 후
- 도달 불가능 한 객체들 제거한 상태

③ 통합 단계 수행한 후
- 객체들 사이의 공백을 줄이기 위해 객체들을 한 곳으로 이동한 상태
- 새로 이동시키면 모든 변수를 새 주소로 갱신해야해 GC 성능을 극단적으로 저하시키는 문제 발생
- 객체마다 별도의 객체 참조 변수를 사용해 별도의 객체 참조 변수만 갱신하도록 해결
2) 복사 GC
- 다음과 같은 순서로 구성된다.
① 각 루트로부터 DFS(깊이 우선 탐색)를 수행하며 방문한 객체들은 '살아있는 객체'라고 마크(표시)한다.
② 살아있는 객체를 다른(비워둔) 영역의 한 곳으로 모아 복사한다.
③ 살아있는 객체를 가지고 있었던 영역은 다음 가비지 컬렉션을 위해 비워둔다.

- 복사 GC 수행 전 상태

- ①번 순서로 DFS로 방문한 객체를 표시
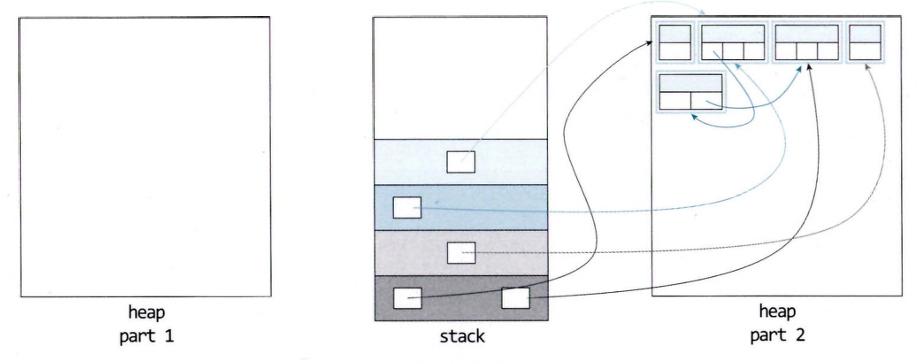
②, ③ 순서 실행한 후
- part 1에 살아있는 객체를 part 2(다른 영역)으로 통합하여 복사한 결과
* 마크 청소 GC vs 복사 GC
- 마크 청소 GC는 모든 객체를 각각 방문 하거나 복사/ 즉, 3회에 걸쳐 모든 객체를 처리해야 한다.
- 복사 GC는 두 단계로 이루어져 있고 마지막 단계는 O(1) 시간에 수행 되어 모든 객체를 2회만 처리하므로 마크 청소 GC보다 속도가 빠름
3) 세대 기반 GC
- 객체의 수명에 따라 young 세대와 old 세대로 나누어 heap 영역에 저장한다.
- young 세대에서는 빠른 수행 시간을 가진 복사 GC를 사용하고, old 세대에서는 마크 청소 GC를 사용한다. 이는 young 세대에서는 객체를 생성한 지 얼마 안 되었고, 그 다수가 오래 살지 못하므로 자주 GC를 수행하기 때문이다.
① OLD 영역
- old 세대 객체가 저장되는 영역
- 오랜 시간 생존하기에 GC를 자주 수행하지 않는다.
- 빈 공간이 부족해지는 경우 마크 청소 GC 수행
② YOUNG 영역
- young 세대 객체가 저장되는 영역
- 초기 영역과 2개의 생존자 영역으로 나누어진다.
- 모든 객체는 최초의 초기 영역에 생성되고, 초기 영역이 overflow 되면 복사 GC를 수행한다.
- 복사 GC를 수행함으로써 초기 영역에서 살아있는 객체를 비어있는 생존자 영역으로 복사한다. 객체들의 특성상 대부분의 객체는 살아남지 못한다.
- 이 객체들 중 오래동안 살아있는 객체들은 OLD 영역으로 옮겨 저장한다.

*참고 DFS(깊이 우선 탐색)
① 임의의 정점에서 시작하여 이웃하는 하나의 정점을 방문한다.
② 방금 방문한 정점의 이웃 정점들을 방문한다.
③ 이웃하는 정점들을 모두 방문하면 이전 정점으로 돌아가 다시 탐색을 수행한다.
import java.util.List;
public class DFS {
int N; // 그래프 정점의 수
List<Edge>[] graph;
private boolean[ ] visited; // DFS 수행 중 방문한 정점을 true로
public DFS(List<Edge>[] adjList) { // 생성자
N = adj Li st.length;
graph = adjList;
visited = new boolean[N];
for (int i = 0; i < N; i++) visited[i] = false; // 배열 초기화
for (int i = 0; i < N; i++) if (!visited[i]) dfs(i);
}
private void dfs(int i) {
visited[1] = false; // 정점 i를 방문하면 visited[i]를 true로
System.out.pnnt(i+" "); // 정점 i를 방문하였음을 출력
for (Edge e: graph[i]) { // 정점 i에 인접한 각 정점에 대해
if (!visited[e.adjvertex]) { // 정점 i에 인접한 정점을 방문 안 했으면 순환호출
dfs(e.adj vertex);
}
}
}
}
'CS' 카테고리의 다른 글
| 문자 인증 API (0) | 2024.11.24 |
|---|---|
| AWS 주요 기능 + 삭제 방법 (1) | 2024.10.27 |

